
传统SDLC的终结:AI驱动的QA原型如何重塑软件测试的未来
引言:当传统节奏被打破
几十年来,质量保证(QA)一直遵循着一种熟悉且基本未变的节奏:需求到达、编写测试用例、执行测试、提交报告。即使自动化测试进入视野,QA的角色也大多被锚定在流水线的末端——步骤被自动化了,但思维没有。这种模式的隐形成本是巨大的:常规性工作不断挤占经验丰富的QA专业人员进行判断和系统性思考的时间。
然而,到了2026年,这一节奏正在被彻底打破。我们不仅在讨论AI如何辅助测试,更是在见证一个AI测试AI编写代码的新时代。本文将带你深入了解一个实际运行的AI QA助手原型,探讨它如何通过自动化分析、生成和执行,将QA从繁琐的重复劳动中解放出来。

AI QA 助手的核心架构:从执行到编排
这个AI测试助手的目标非常宏大:只需输入一个URL,系统就能自动分析页面,根据业务需求生成测试用例,通过浏览器执行,并生成一份专业的QA报告。整个过程仅需几分钟,而且是由具有测试背景而非深厚开发背景的团队构建的。
其背后的技术架构简洁而强大:
- RAG系统 (LangChain + Milvus):通过向量嵌入处理业务需求,实现相关信息的上下文搜索。
- AI引擎 (Claude API):负责页面分析、测试用例生成以及报告洞察的创建。
- 测试执行 (Playwright):负责浏览器自动化,在每一步记录日志并截图。
- Web界面 (Flask):提供配置、实时日志查看和结果交互。
- 报告引擎:生成带有视觉总结和AI建议的HTML报告。
自动化测试的五个阶段
以Google搜索测试为例,该系统在点击“运行AI测试套件”后,会自动经历以下五个阶段:
1. 发现阶段 (Discovery)
Playwright打开浏览器,分析DOM结构,识别所有交互元素(按钮、输入框、链接)。
2. RAG处理
系统将业务需求转化为向量,并寻找与当前页面测试相关的上下文。例如,需求规定“搜索输入框必须可见且可交互”。
3. 测试生成
Claude API接收页面结构、业务需求和RAG提供的上下文,生成带有特定选择器(Selectors)的详细测试用例。
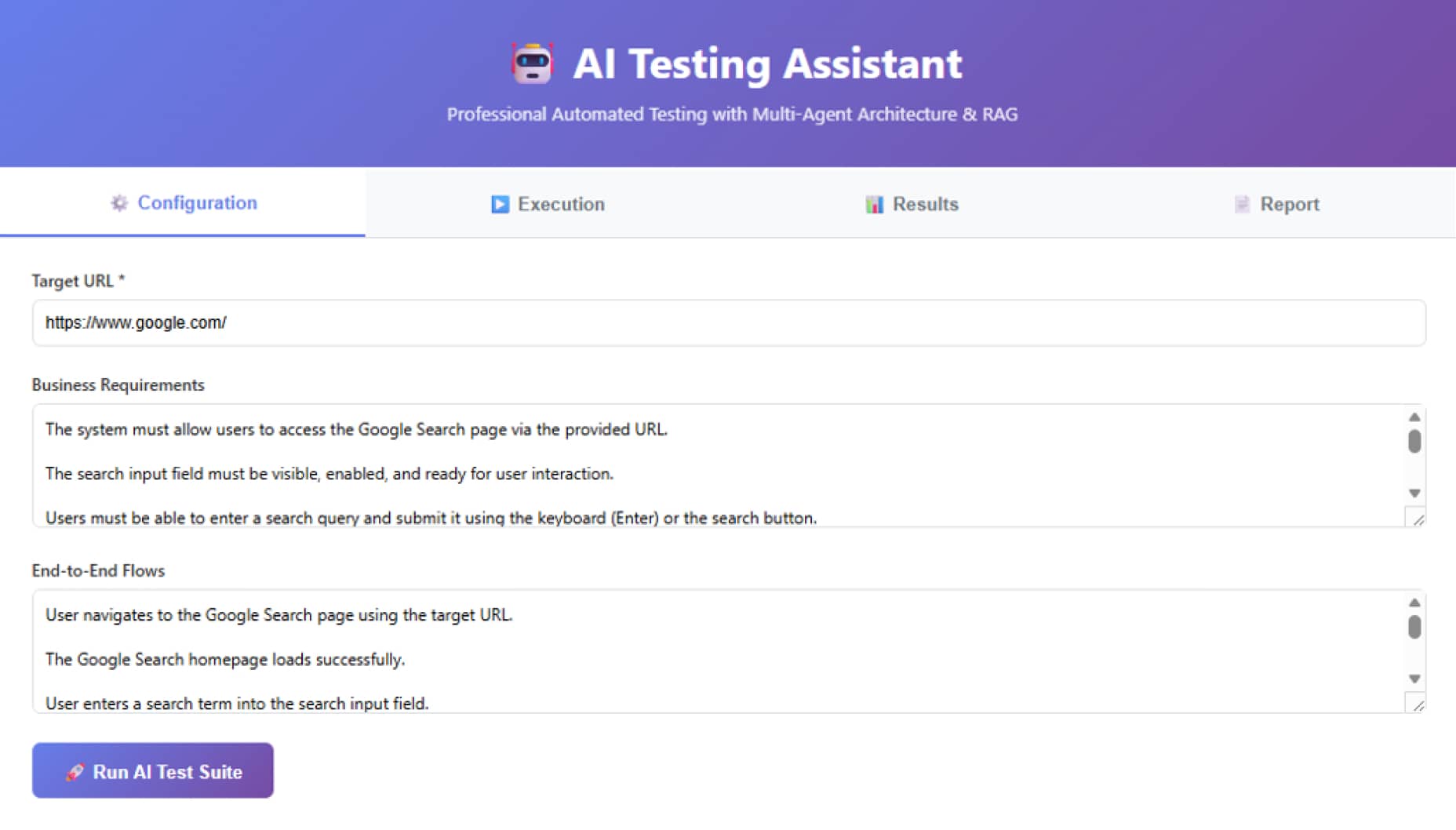
4. 执行阶段
Playwright逐一执行测试步骤,捕获异常并保存关键路径的截图。
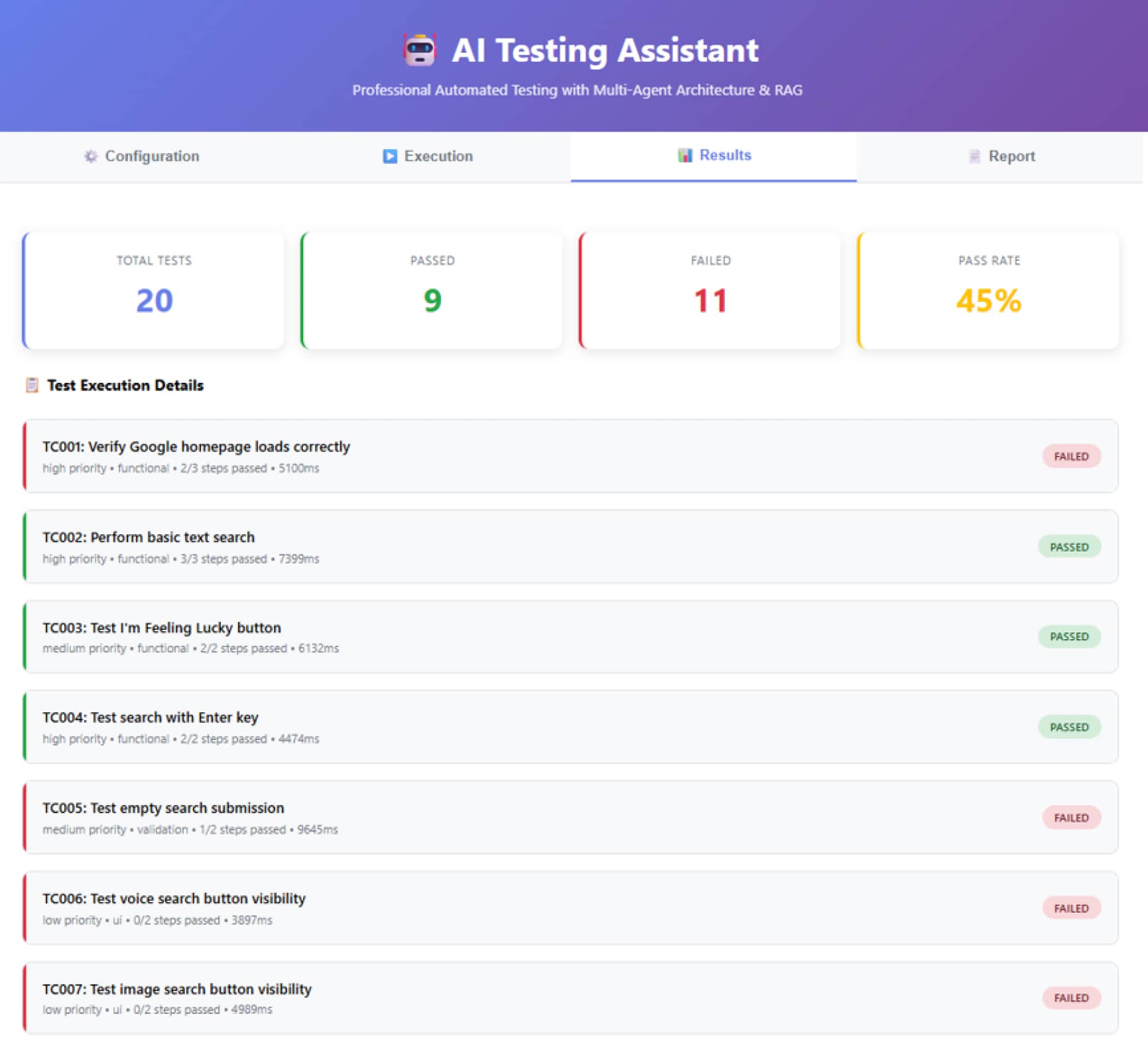
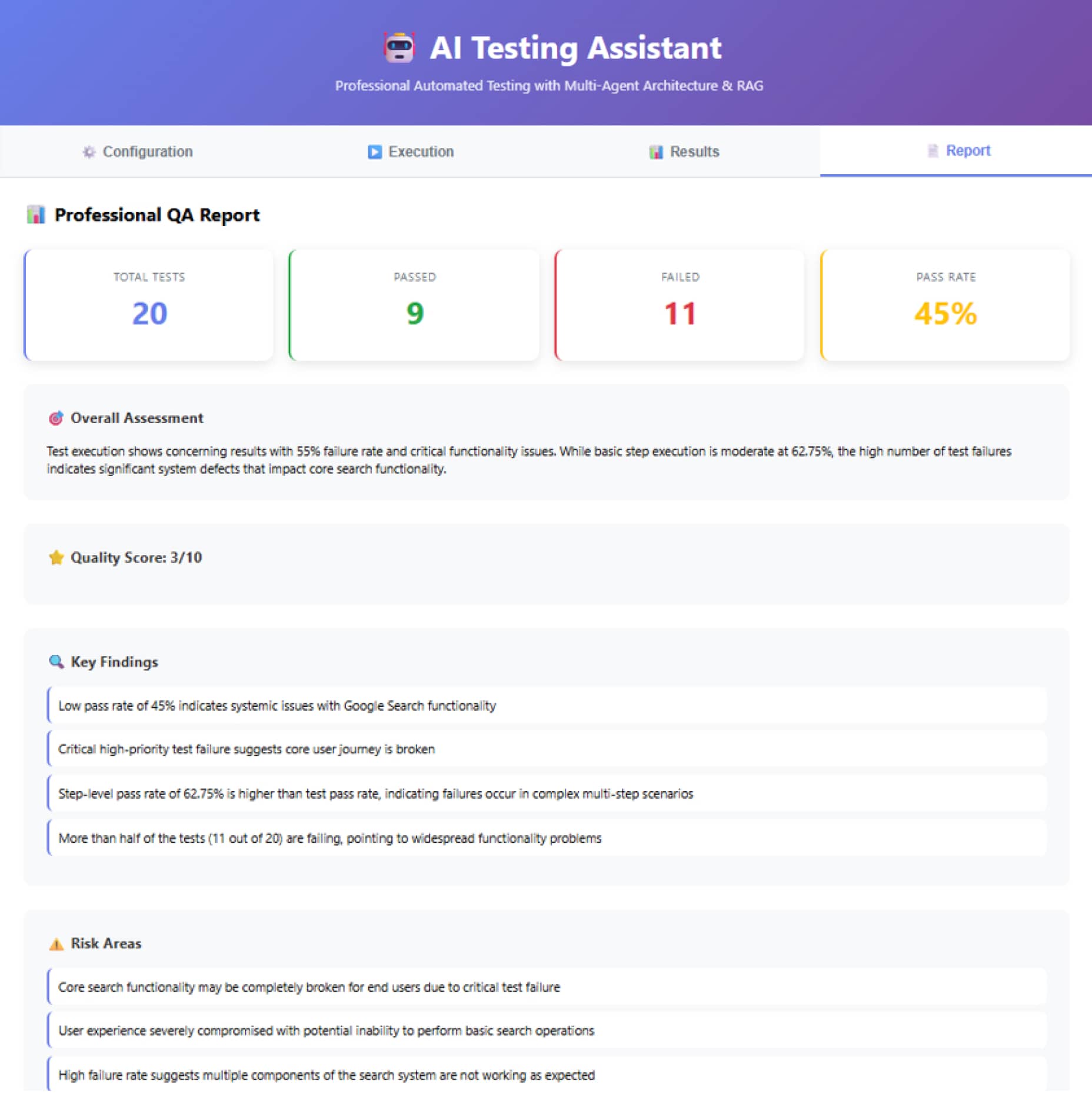
5. 报告与分析
AI分析执行结果,识别出不仅仅是“通过/失败”的数字,而是深层的原因。例如,在一次实际测试中,系统得出了45%的通过率。虽然数字不高,但AI指出了核心问题:定位器(Selectors)受本地化影响严重。由于乌克兰语界面的元素属性与默认设置不同,导致了大量失败。

2026年的新现实:从确定性到概率性
随着AI推理能力的提升,QA的角色正在发生根本性转变。正如《2026年AI指数报告》所指出的,QA工程师的工作重点正在从“验证结果”转向“验证系统行为”。
这种转变体现在以下三个方面:
- 从确定性到概率性:AI生成的代码和行为不再是完全预期的,测试需要处理输出的不一致性。
- 从功能测试到AI行为测试:关注系统的安全性、一致性和道德合规性。
- 绿色测试 (Green Testing):这是一个新兴概念,强调优化自动化测试的资源消耗,减少CI/CD流水线的碳足迹和计算成本。
QA的新使命:不仅是运行测试,而是设计测试系统
这个AI助手的原型证明了:QA的未来不再是手动编写每一个脚本,而是编排AI来构建所需的工具。这意味着QA的门槛正在提高,虽然常规任务被自动化了,但对风险分析、域知识和系统性思维的要求却变得更高。
"昨天,QA被期望去运行测试。今天,QA可以创建一个运行测试的工具。"
这种转变让QA工作变得更具挑战性,但也更具意义。QA不再是在流水线末端“找茬”的人,而是质量逻辑的塑造者。AI并没有取代人类的判断,它只是放大了个人的专业能力,让QA能够以更快的速度、更大的规模交付用户可以信赖的产品。
结语:拥抱变革
AI QA 原型不仅仅是一个工具,它代表了对质量保证工作方式的重新构想。在未来,我们关注的不再是“我们测试得够多吗?”,而是“这个系统能可靠地测试最重要的部分吗?”。在这个AI测试AI的新现实中,只有那些能够驾驭AI工具、深刻理解业务逻辑并进行系统性思考的QA专业人士,才能在竞争中脱颖而出。